
如何掌握B端用户的信息需求?我总结了这3种!
一、复杂系统的交互
我是做 B 端系统的交互,干这行的朋友都知道 B 端系统很复杂,对用户搜寻信息、完成任务的能力有很高的要求,使用这种系统也往往不像你刷抖音、逛淘宝一样轻松。
针对如此复杂的业务情况,我时常会感觉当前我们“交互设计”或者“体验设计”这一行的行业知识基础还是不太扎实。我们大家都知道,“交互设计”作为一个极为应用性的方向,就像一张桌子,桌面上的东西是具体的界面设计知识,比如控件设计、页面排版,而桌子的四条腿则是心理学/社会学/人因学/信息科学等等稍微偏向于基础研究的学科。
因此本周我找了一本信息科学领域对信息搜寻行为的入门级读物,从别的学科切入交互设计,看一看对我们的日常工作有没有什么启发。实际上信息科学和交互设计很有渊源,比如我们现在在使用的“信息架构”这个概念就和信息科学有千丝万缕的联系。而且信息科学的最初的研究领域就是研究图书馆或者公司组织这种大型数据库的,正好跟 B 端设计师的工作范围不谋而合,所以读下来的确感觉还挺有启发。今天我就摘录其中“用户信息需求分析”一节,结合我的个人感受写一点东西。

“信息”的定义在学界是复杂多变的,甚至到今天也并没有形成一致的定义。在香农那个年代对信息的定义是“降低事物的不确定性”,在此基础上结合实验衍生出了我们熟悉的费茨定律。但这个定义明显不怎么考虑人的主观因素,也不太符合直觉,是一个很费脑子的定义。
很明显学术界也有很多人有类似的看法,因此信息科学这个经过本世纪的发展,从一开始的只侧重于信息系统的构建,到今天也加入了很多心理学/社会学的视角和研究方法,和我们设计今日“以用户为中心”的核心思路也是有些类似的。
在这些不同的视角下,作者归纳出了 4 种对“信息”定义和用户信息诉求的不同理解方式,下面我把它简写为 3 种。不同的研究者从不同的角度解释了“为什么我们的用户需要信息,他们对信息的诉求有什么差异,这种需求的差异又会形成什么样的行为差异”这个困扰我们交互设计师的问题。虽然他们作为研究者的思路是比较抽象的,但归纳出来的方式其实的确都能在我们的工作中找到一些现实依据,也是一个很妙的事情。
二、用户为了获得答案而寻找信息
罗伯特·泰勒在 1968 发表了一篇对用户(人)的信息需求的讨论。他坐在图书咨询台旁边观察来来往往的咨询者,发现每个人的咨询行为都很不一样,而且这种不一样似乎可以被分成成几类或者几种阶段。
第一类阶段的信息需求无法用言语解释清楚,用户只能表达一种“模糊的不满”,一种对信息“脱口而出的无意识的诉求(Visceral need)”。
第二类需求则是有意识的,但用户还是不能很有条理地说清楚自己到底要找什么,他们的陈述往往是模棱两可并且颠三倒四的。
第三类需求终于逐渐结构化,用户可以用言语表达出自己要问什么问题、找什么东西,但用户不知道上哪里去找,也不知道自己应该找谁。比如这个信息可能出现在哪个系统里?我应该找综合咨询处的工作人员问,还是应该找哪个图书区的专员问?
最终,第四类需求是高度结构化的,持有这类需求的用户很清楚系统会反馈给他们什么样的数据,只是不知道自己应该怎样与系统交互(比如输入什么样的词句),才能更好地匹配到自己想要获得的信息。

他对这种现象举了个例子。比如一个读者来图书馆的实际目的是为了了解不同哲学家对一个哲学概念的不同见解,但因为他个人的特质、他对图书馆系统的了解、他的过往经历等等因素,他无法将这个问题非常结构性的表达出来,比如“你能用你的图书系统帮我搜索一下含有某哲学概念的哲学书籍能在哪个架子上找到吗?”。相反,他会来图书馆问一些非常宏大的、没头没脑的问题,比如“你们有哲学书吗?”
他期望的不是图书管理员跟他说“对,我们有哲学书”,而是希望图书管理员帮他澄清问题、进一步的缩小检索范围,比如“你想找哪类型哲学书呢?”
这个视角在 B 端设计中的价值主要是提醒我们需要对用户能力做正确的预估,以及一定要为用户搭建稳定的概念模型。
从用户能力来说,虽然书中这一节并没有提到造成这种需求差异的原因,但根据我的经验,用户本身的受教育程度、思维方式、使用复杂产品的经验都会造成类似的信息需求的差异。我觉得业内一个特别不好的倾向是总把 B 端产品理解为“高能力用户的产品”或者“专家用户的产品”,但实际上 B 端产品的用户根据行业的不同,涵盖的情况相当广泛,也不乏上文说的那样“说不清楚自己要找什么”的情况出现。
从概念模型的角度上来说,B 端产品可能因为各种各样的原因,有非常多的互相毫无联系的子系统。这就会让用户(特别是新用户)对“我能看到什么信息、我可以获得什么样的服务”毫无概念。在这种对系统整体边界没概念的状态下,用户也就总是停留在第三类需求的状态下,信息获取的效率很低。
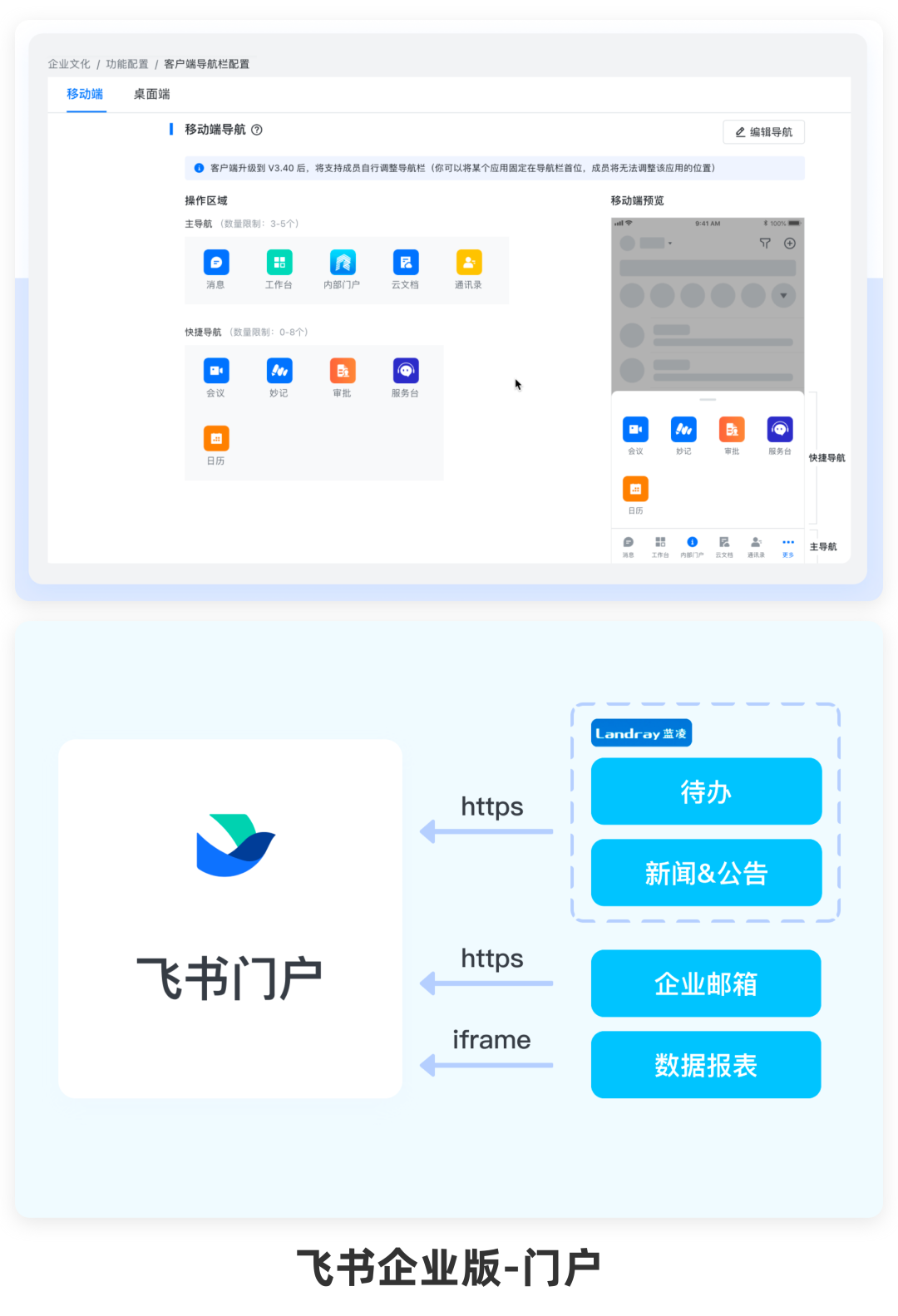
比如钉钉/飞书企业版都提供了一个“集成不同系统,在飞书上建立信息门户”的功能。简单来说就是公司购买这些企业版软件后,可以把自己的一大堆乱七八糟的邮箱/数据看板/后台等等以信息展示或者功能入口的形式“挂”到上面去,在聊天软件上形成一个企业门户。
为啥要搞一个所谓“门户”呢?从信息获取的角度上来说,也是因为这些散落在各处的服务需要用一个集合入口去让用户对企业所有服务形成整体概念,从而更可能提高信息需求的结构化程度。从“这东西有没有?我该上哪找?”过渡到“怎么找更快?”
三、用户为了降低不确定性而寻找信息
一听到“不确定性 uncertainty”这个东西就知道又是香农那一套了,但是今天我们不再讲费茨定律,而是聊一聊用户在努力降低信息不确定性时的心理感受。
查尔斯 · 阿特金在 1973 年将“信息需求”定义为“个人对重要的环境对象的当前不确定性水平与他期望状态之间的差异”。简单来讲,就是我们的用户对自己当前知识的评估,和他认为的理想状态的对比。比如一个用户自认为自己完全不会弄一个复杂的申请流程,并且他认为自己的岗位应该对这个申请流程特别熟悉,他就会受这种落差和自己的动力驱使,去不停的查找这个流程的相关知识和细节。
这个过程中往往伴随着很高程度的焦虑,并且因为知识的搜索本质上是无穷无尽,精益求精的,因此这个用户何时停下检索更多的取决于他的动机有多强。比如这个学习者是个产品经理,在弄清楚了申请流程,他下一步可能还想弄清楚为什么要搞这么多步骤,每一步是为了什么,再下一步想弄清楚这个申请流程的迭代过程……
研究者还发现,我们了解信息的动机往往不像我们经常做设计分析时那样理性、清晰、目标明确。也就是说,很多时候用户希望了解信息并不是因为他们想要用这些信息去分析啥,而是受“模糊的不安感,一种知识空白的感觉”所驱使,这是一种感性的情感需求。

读到这里我的第一感受就是,这太体现情感化设计的重要性了。在我们的交互设计中,人对信息的理性需求往往被高估。比如我做表单或者做大表格的时候总是会去问用户“这个信息为什么对你很重要?”、“你要用这个信息去干嘛呢?”
但实际上用户需要的可能并不是事无巨细的、机械式的信息透传,而是一种“对整体情况的理解”、一种“了解信息的安全感”,在这种安全感中,用户不会过高的预估自己掌握信息的必要性(因为他假设自己了解全局、他假设系统不会坑他)。虽然基础的信息透传还是必要的,但假如我们的用户没那么焦虑,是不是也就不必要持续进行地毯式的信息搜寻行为,生怕遗漏一丝细节?

当然这种所谓的“情感化”不仅仅是指画多几个表情包或者写几句暖心文案。放在交互设计师面前的难题是,我们如何通过设计的形式去缓解用户的信息焦虑,为他们创造一个“不需要太专业也可以轻松使用我们 B 端软件”的概念与环境?视觉上的设计是一方面,但框架层及以上还有更多可探索的空间。
四、用户为了构建意义而寻找信息
这个研究很有意思,持这种观点的研究者认为我们生活中的信息存在不连续性,而这种不连续性就造成了用户认知的鸿沟或者裂隙。用户需要根据自己的诉求、动用自己的经验、寻找各种信息,并且不断尝试对信息进行归类、比较,最终内化信息,填补自己认知上的的“裂隙”。
这个理论横跨了数个学科,实在是有点抽象,但好在作者在 93 年在咱们交互设计相关的会议上发表了一篇文章,举例详解用户的这种类似构建信息架构的意义构建过程,所以其实咱们看他的例子也能差不多理解。接下来我就为大家讲解一下。
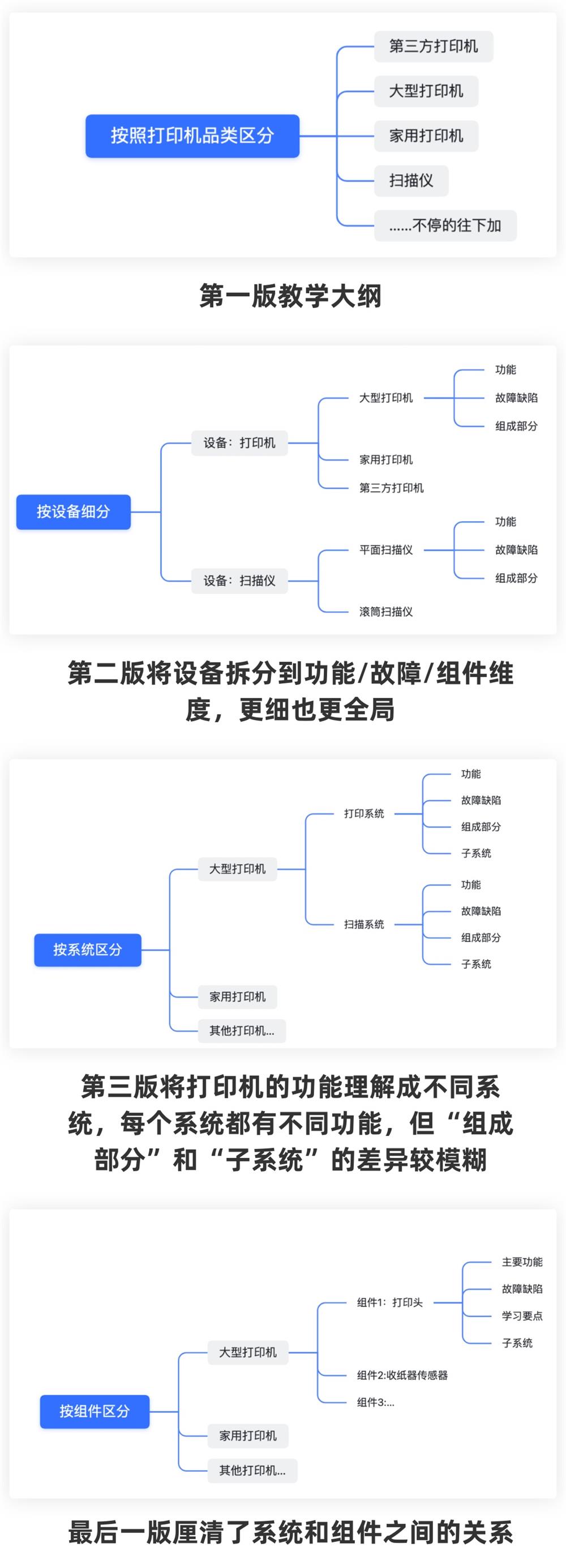
这个研究者在 1989 年观察了施乐(Xerox)公司的一个公司内部培训课程开发流程。当时施乐有几十种不同型号的打印机和扫描仪,每台打印机都有 10-20 份文件记录,每份记录从 30-300 页不等。因为这些记录内容都没有结构化,所以这个内培小组之前的课程都是基于某几种特定的打印机类型研发的,不好推广到所有的打印/扫描仪。
举个例子,就像九阳有一大堆不同型号的豆浆机和破壁机,每个的功能和参数都有一些不同。有的有免滤豆渣功能、有的有加热烹煮功能,有的转速高、有的转速低,有的底部是塑料做的,有的是陶瓷做的。都不一样,也没人画个大表格归类一下。

因此,内培部之前的课程研发只针对某款特殊的“免滤豆渣豆浆机”开发,讲这部机器转速如何、烹煮功能怎么用,有什么设计缺陷要注意等等。假如九阳的销售业务员都这样一个个机器挨个学,那显然效率太慢了,所以内培部门想了一个招:
- 将机器分几个大类,先让销售们对我们九阳的产品建立一个大概认知,后续好深入。
- 把学习流程模块化,比如有 3 种机器都有“烹煮功能”,那咱们就专门开一节课讲解咱们这个功能使用场景是啥、主要怎么用、对应的该如何维护等等,这样学起来就快多了。并且模块化/结构化的信息也能更好地支持对豆浆机/破壁机的分类。
但是对于施乐的内培部门来说,打印机的参数巨多,分类方式也很多。面对如此复杂的情况,他们应该如何做到合理分类、模块化这两件事呢?换句话说,他们怎样从这些一盘散沙的信息中构建意义?
研究者发现,这分成 3 个核心阶段:
- 抓特征、抓差异:课程的开发者会从这些零散的打印机说明文件中总结出一些代表性特征,比如“底座制作工艺”这个特征可能包含了“陶瓷、塑料”
- 找到特征对应的具体案例:也就是尝试把文件中的一些相关的信息点放到具体特征中,比如我看见这个豆浆机的文件里有描述它的“底部由金属构成”,那我就给它归成“底部制作工艺:金属”。在这个过程中逐渐形成整个信息框架。
- 对特征进行增删:那些没有具体案例的、和案例不匹配的特征会被删除或者修改。比如我找到好几台豆浆机的制作工艺是“全体金属,底座橡皮包边”,那么“底部制作工艺”这个分类好像就不太能容纳这种案例,我可能会把“底部制作工艺”这种特征/分类调整为“制作工艺”,下面有两个子分类“一体制作”和“分体制作”。
用户就是在在自上向下的“特征找案例”和自下向上的“抓特征、抓差异”过程之间不同的循环迭代,最终建立起一套比较稳定的体系,从而建立意义和逻辑。这个过程会充满了不确定性,随时会对特征进行修改。简单来说,用户完成任务的时间=建立概念的时间+真正去进行操作或者产出的时间。
在这个循环过程中,施乐的打印机课程研发小组一共迭代了 4 版不同的教学架构。最后选择了第四种。为什么第四种更好?根据作者的陈述,是因为这样表示出了一种递归结构,有利于构建全局性的信息编码(可以理解为全局的标签系统),后续可以进行自动化的聚类分析。这里我们就不展开了,以后再聊。
从这个视角来看用户的信息诉求或者意义构建行为,其实有两个特别有意思的点:
- 施乐这个构建课程的过程其实极其类似我们交互设计师搞信息架构的流程。
- 这个模型非常强调用户花在“理解清楚事情全貌”这件事上的时间,而不像菲茨定律一样极端强调用户花在具体操作上的时间。
首先从信息架构的角度来说,虽然一开始信息架构:超越 web 的什么什么那本书就有提到“自上而下”、“自下而上”地构建产品的组织系统这么一回事,但是他只是轻轻的掠过了这两个概念,具体的提炼过程比较语焉不详。
在这个案例里我们可以清晰的看到施乐这帮人是如何将“自下而上的聚类提炼”和“自上而下的分类归纳”这两个行为循环往复的做,从而产出一个比较稳定的、可以涵盖大多数信息的框架。那么我们作为交互设计师做信息架构的价值就是帮助用户省略到这个“咀嚼信息”的过程,让他直接跟着我们的思路走就能“消化信息”。
从用户花的时间的这个角度来讲,我们在做设计的时候,特别是做 B 端设计的时候,很多产品经理往往希望你能把所有能展示的东西全部铺开给用户,好像提升信息的展示速度就等于用户对信息的获取效率提高了。从这个视角来看,完全不是这么一回事。
你东一榔头西一棒子的提供给用户大量信息,其实就是给用户的“意义构建”提供了一个巨大的难题,他需要在这个页面上“抓特征差异”,然后“抓案例”来验证自己的思路,还要不断修改自己对这一摊子事物的抽象理解模型,然后才能真正进行操作。这个视角在我来看是对菲茨定律的一个挺好的补充。
作者:白话说交互
想了解更多网站技术的内容,请访问:网站技术













